
由于絕大多數(shù)細(xì)菌和古細(xì)菌尚未被成功培養(yǎng),因此它們的基因組、新陳代謝潛力以及在環(huán)境中的功能仍未得到充分研究;我們將這些微生物稱為微生物暗物質(zhì)[1-5]。單細(xì)胞基因組學(xué)是研究微生物暗物質(zhì)的重要手段,但全基因組擴(kuò)增步驟存在諸多挑戰(zhàn)。傳統(tǒng)全基因組擴(kuò)增方法(MDA)雖常用,但成本高且對特定基因組區(qū)域存在擴(kuò)增偏差,導(dǎo)致基因組覆蓋不均,限制了其在高通量研究中的應(yīng)用,難以獲取高質(zhì)量基因組,尤其是微生物群落中的少數(shù)類群基因組[6,7]。
在微生物研究領(lǐng)域,單細(xì)胞基因組學(xué)(SCG)為探索微生物暗物質(zhì)(MDM)提供了關(guān)鍵途徑[8-10]。然而,全基因組擴(kuò)增這一關(guān)鍵步驟面臨諸多挑戰(zhàn),如成本高昂、擴(kuò)增偏差以及污染問題等,嚴(yán)重制約了研究的深入開展。
I.DOT非接觸式移液器的技術(shù)核心及優(yōu)勢

非接觸式液體轉(zhuǎn)移:在納升至微升范圍內(nèi),實現(xiàn)極低死體積(<1 μL)和零交叉污染風(fēng)險的液體轉(zhuǎn)移,為細(xì)胞培養(yǎng)提供前所未有的精確度和安全性。
Drop Detection系統(tǒng):對每個液滴進(jìn)行計數(shù)和檢測,確保實驗的可重復(fù)性和可靠性,提高實驗效率。
本篇推文主要介紹I.DOT 技術(shù)在微生物單細(xì)胞全基因組擴(kuò)增研究中的應(yīng)用。旨在解決傳統(tǒng)全基因組擴(kuò)增方法(如MDA)成本高、擴(kuò)增偏差大及污染等問題,為微生物單細(xì)胞基因組學(xué)研究提供新方法。
實驗方法
第一步:細(xì)胞培養(yǎng)與分離
培養(yǎng)大腸桿菌 K12 MG1655 至指數(shù)生長期,在UV-去污染的 ISO 4級潔凈室中處理,用 BD FACS Melody 將細(xì)胞分選至384孔板,低溫保存。
第二步:細(xì)胞裂解
采用改良裂解緩沖液[11],通過I.DOT mini將裂解液分配到細(xì)胞上并放入不含細(xì)胞的孔中(陰性對照)。在21℃下孵育10分鐘,通過加入等體積的中和緩沖液來中和。
第三步:多重置換擴(kuò)增(MDA)
用 REPLI-g單細(xì)胞試劑盒進(jìn)行MDA反應(yīng),然后用I.DOT mini將REPLI-g主混合液分配到裂解的細(xì)胞和陰性對照上,使最終的MDA體積為0.5, 0.8, 1.0, 1.25, 5, 10 μL。MDA在CFX-384熱循環(huán)器(Bio-Rad, Hercules,CA,USA)中在30℃下孵育6小時,然后在65?C下孵育10分鐘以停止擴(kuò)增并保持在4℃。擴(kuò)增的DNA保存在?20℃,直到用于文庫準(zhǔn)備。
第四步:文庫制備與測序
在紫外線凈化的層流PCR工作臺進(jìn)行相關(guān)操作,包括純化、文庫制備,最后用 Illumina NextSeq 550 測序。
第五步:數(shù)據(jù)處理及分析
使用多種工具進(jìn)行質(zhì)量檢測、修剪、歸一化、去污染、去重、比對、組裝和質(zhì)量評價[7,12-19]
1、使用FastQC和Trim Galore軟件對序列數(shù)據(jù)進(jìn)行質(zhì)量檢查和修剪。
2、用BBTools軟件將修剪后的數(shù)據(jù)標(biāo)準(zhǔn)化到約200倍的測序深度,并進(jìn)行了不同深度(100×, 80×, 60×, 40×, 20×)的下采樣,以分析測序深度對覆蓋度的影響。
3、使用FASTQ-Screen軟件對數(shù)據(jù)進(jìn)行污染評估,并保留大腸桿菌的多映射讀取。
4、利用BBTools軟件去除PCR重復(fù)序列。
5、將讀取數(shù)據(jù)映射到大腸桿菌MG1655參考基因組,并計算10 kb區(qū)間的覆蓋度。
6、在進(jìn)行de novo組裝前,使用bbnorm.sh軟件對讀取覆蓋度進(jìn)行標(biāo)準(zhǔn)化。
7、使用SPAdes軟件進(jìn)行單細(xì)胞模式下的組裝,并用QUAST和MDMcleaner軟件評估組裝質(zhì)量和污染程度。
8、使用Microsoft Excel進(jìn)行統(tǒng)計分析,包括ANOVA和Kruskal-Wallis測試,以及t-Test進(jìn)行成對比較。
9、使用R軟件的ineq包計算Gini指數(shù),并用ggplot2創(chuàng)建讀取深度和Lorenz曲線圖。
實驗數(shù)據(jù)分析
1、在384孔板上進(jìn)行總反應(yīng)體積為0.5、0.8、1.0、1.25、5.0和10 μL的MDAs(表A1)。最小濃度0.5μL的MDA反應(yīng)不起作用,0.8 μL和1.0 μL反應(yīng)的擴(kuò)增成功率分別只有68.75%和62.50%。相比之下,1.25 μL MDA反應(yīng)的成功率為87.50%,而5.0 μL和10 μL MDA反應(yīng)的成功率均為100%。在較低的丙二醛反應(yīng)體系中,較低的成功率可能是由于在小體積中聚合酶的蒸發(fā)或位阻[20,21]。平均而言,放大達(dá)到檢測閾值所需的時間(用Cq);1.25 μL的MDA反應(yīng)體積(圖1A)反應(yīng)時間最早。先前的研究報道,Cq值越早,基因組恢復(fù)成功率和質(zhì)量越高[11,22]。此外,我們檢測到的相對熒光(RFU)終點和成功反應(yīng)的DNA產(chǎn)率隨著反應(yīng)體積的減少而下降(圖1A,B),最初表明體積的減少可能限制了MDA的指數(shù)性質(zhì)[23,24],這應(yīng)該提高基因組的覆蓋率和均勻性。為了進(jìn)一步比較WGA反應(yīng)的質(zhì)量,根據(jù)Cq和RFU值選擇每種不同MDA反應(yīng)體積的5個擴(kuò)增重復(fù),然后使用等量的DNA進(jìn)行Illumina測序。
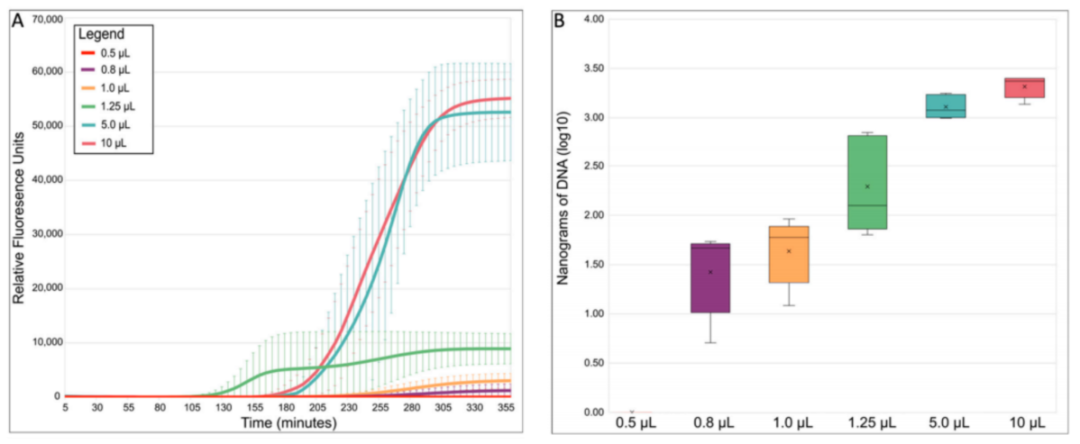
圖1. MDA反應(yīng)統(tǒng)計概述。(A)平均丙二醛反應(yīng)動力學(xué)的反應(yīng)大小。標(biāo)準(zhǔn)誤差條表示使用每個反應(yīng)體積的所有五個重復(fù)計算的標(biāo)準(zhǔn)偏差。(B)按反應(yīng)大小計算的MDA平均擴(kuò)增率。相對熒光單(RFU)指SYTO?-13用實時熱循環(huán)儀測得的熒光信號。SYTO?-13用于監(jiān)測MDA的進(jìn)展,因為它在擴(kuò)增時與雙鏈DNA結(jié)合。方框的中線代表中位數(shù),x代表平均值。用5個重復(fù)進(jìn)行計算。
2、不同MDA反應(yīng)體積在讀取修剪過程中丟失的讀取數(shù)量存在顯著差異(圖2A),其中1.25 μL的MDA反應(yīng)體積在讀取質(zhì)量修剪中丟失的讀取數(shù)量顯著少于其他體積(p ≤ 0.05)。修剪后,所有樣本被標(biāo)準(zhǔn)化到200×測序深度,以便公平比較不同反應(yīng)體積的映射和組裝質(zhì)量。盡管較大體積反應(yīng)的平均重復(fù)讀取數(shù)量較多(圖2B),但差異并不顯著(p = 0.0870)。這可能與大體積MDA反應(yīng)中模板特異性較低有關(guān)[25,26],導(dǎo)致更多的錯誤引物結(jié)合和擴(kuò)增,尤其是在模板濃度非常低時。此外,較大的反應(yīng)體積在過濾后去除的污染讀取也較多(圖2C),這可能是由于背景污染與大腸桿菌單細(xì)胞DNA之間的競爭增加所致[25,27]。總的來說,5和10 μL的MDA反應(yīng)體積結(jié)果一致性較差,表現(xiàn)為重復(fù)之間的變異性較大(圖2)。
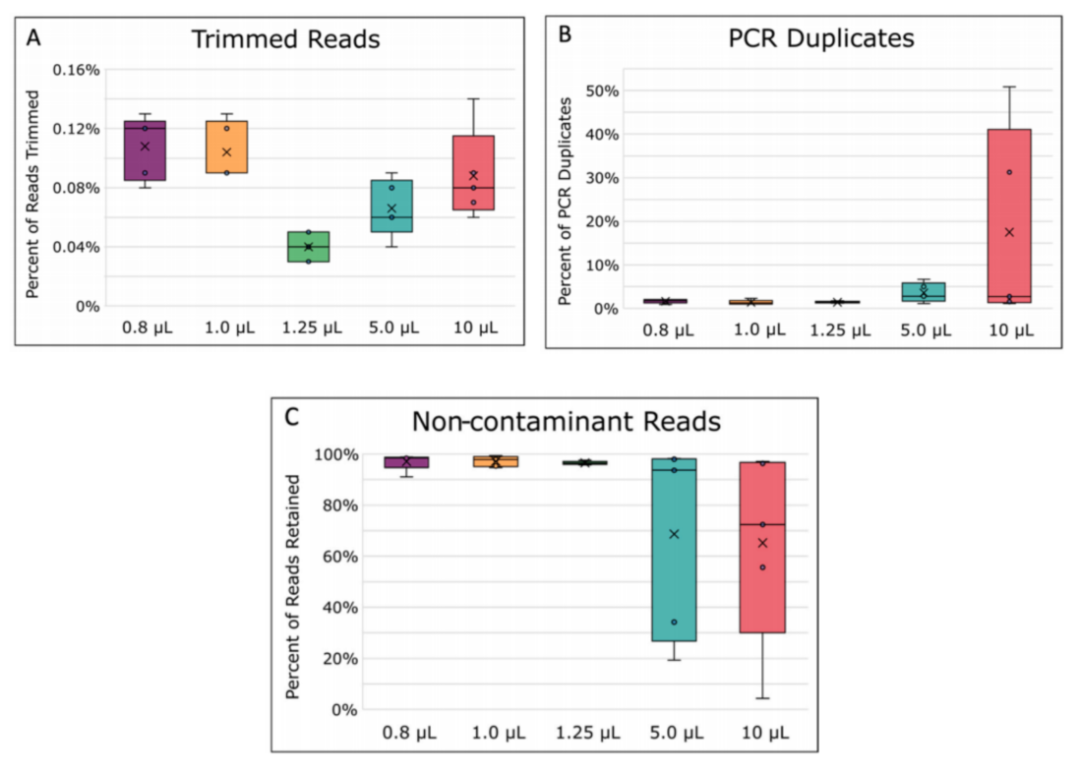
圖2. 讀取處理統(tǒng)計數(shù)據(jù)。(A)在質(zhì)量修剪期間去除讀數(shù)的百分比。(B)去除PCR重復(fù)的百分比。(C)讀數(shù)污染物過濾后保留的讀數(shù)百分比。方框的中線代表中位數(shù),x代表平均值。用5個重復(fù)進(jìn)行計算
3、由于模板特異性較低,高于1.25 μL的MDA反應(yīng)量在對參比大腸桿菌MG1655基因組的讀取定位中也表現(xiàn)較差,如基因組覆蓋寬度和覆蓋均勻性所示(圖3A,B)。而1.25 μL的反應(yīng)體積在384孔板中被認(rèn)為是改善MDA的“最佳點”。1.25 μL MDA反應(yīng)體積的平均讀取覆蓋了大腸桿菌基因組的85%,比其他體積的反應(yīng)高出19%到40%(圖3A)。與WGA-X?方法相比,我們的覆蓋度提高了約19%,即使在讀取映射過程中使用了大約200萬更少的讀取。此外,1.25 μL反應(yīng)體積的覆蓋度均勻性更高,這通過Lorenz曲線和Gini指數(shù)(衡量覆蓋度均勻性的指標(biāo))得到了證實,Gini指數(shù)在1.25 μL反應(yīng)中最低,表明其覆蓋度最均勻(圖5B)。這些結(jié)果表明,1.25 μL的MDA反應(yīng)體積在提高基因組覆蓋度和均勻性方面具有顯著優(yōu)勢。

圖3. 基因組覆蓋率和覆蓋一致性偏差。(A) 在大腸桿菌基因組的10kb區(qū)間內(nèi)計算每個復(fù)制的讀取深度。圖表顯示了每個反應(yīng)體積的所有重復(fù)的平均值。Cov. 是平均覆蓋寬度,即至少一次讀取覆蓋的基因組位置的百分比。(B)在大腸桿菌基因組的10kb區(qū)間內(nèi)計算讀取覆蓋率和深度的均勻性,并對每個反應(yīng)體積的所有五個重復(fù)進(jìn)行平均。
4、對所有復(fù)制的單放大基因組(SAGs)進(jìn)行了組裝和比較。結(jié)果顯示,由于MDA引入的大差異,我們在組裝前將讀取深度標(biāo)準(zhǔn)化至100×的目標(biāo)深度。然而,小于和大于1.25 μL的MDA反應(yīng)體積由于在預(yù)處理步驟中丟失了更多讀取,導(dǎo)致最終序列深度較低,從而使得組裝質(zhì)量較1.25 μL MDA反應(yīng)體積的組裝結(jié)果差(圖4A-C)。具體來說,1.25 μL反應(yīng)的平均總長度和N50(代表50%總序列長度的最短contig序列長度)分別為3,522,851 bp和46,179 bp(圖4B,C),表明這些組裝更加連續(xù),質(zhì)量更高。同時計算了組裝覆蓋度和完整性,覆蓋度是指與參考基因組映射的組裝(contigs)的百分比[70],而基因組完整性則是通過MDMcleaner估計標(biāo)記基因的存在。1.25 μL MDA反應(yīng)的組裝覆蓋度和完整性顯著高于其他體積,平均約為75%和94%,污染最低(圖6D-F)。其中三個1.25 μL MDA反應(yīng)復(fù)制的覆蓋度甚至超過了75%,最高達(dá)到89.5%。相比之下,WGA-X?即使使用了約5倍多的讀取,大腸桿菌組裝覆蓋度也低于60%。我們的10 μL MDA反應(yīng)的組裝覆蓋度與WGA-X?在10 μL反應(yīng)中報告的范圍一致,這表明WGA-X?也可能從進(jìn)一步的體積減少中受益。與其他體積減少方法相比,我們的更高組裝覆蓋度與之前報告的大腸桿菌MDA在皮升級液滴(88-91%)[28]和納升級液滴(88-94%)[27]中的覆蓋度范圍一致。
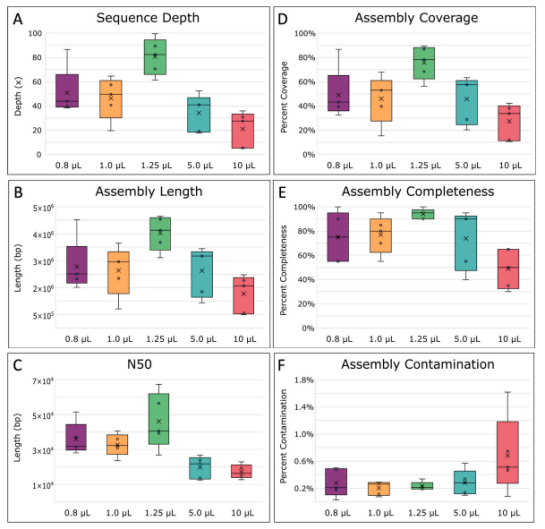
圖4. 單擴(kuò)增基因組(SAG)組裝統(tǒng)計。(A)最終序列深度,以基因組內(nèi)每個堿基平均測序的估計次數(shù)計算。(B)組合的總平均長度,(C) N50平均值,支持50%基因組組合所需的最小組合長度,(D)整個基因組中組合的覆蓋率百分比。大腸桿菌MG1655參考基因組,均采用QUAST測定[13]。(E)組裝基因組的完整性和(F)組裝中受污染堿基的百分比,用MDMCleaner[7]測定。方框的中線代表中位數(shù),x代表平均值。用5個重復(fù)進(jìn)行計算。
總結(jié)與討論
總體而言,1.25 μL 的 MDA 反應(yīng)體積顯著優(yōu)于傳統(tǒng) 50 μL反應(yīng),成本降低約 97.5%,基因組覆蓋度和均勻性大幅提升,產(chǎn)生更完整、偏差更小的單擴(kuò)增基因組(SAGs)。相比其他體積降低方法,該方法在標(biāo)準(zhǔn)384孔板中更易操作,可提高微生物單細(xì)胞基因組學(xué)研究可行性,有助于深入探索微生物多樣性和功能,特別是針對稀有物種和微生物暗物質(zhì)研究。I.DOT技術(shù)在本研究中的應(yīng)用,不僅提高了單細(xì)胞基因組擴(kuò)增的效率和準(zhǔn)確性,還降低了成本,使得SCG更易于在未來的研究中應(yīng)用。這項技術(shù)為研究3D細(xì)胞培養(yǎng)模型中的細(xì)胞信號傳導(dǎo)提供了強(qiáng)大工具,有助于在更接近生理條件下研究各種生物學(xué)過程,為組織工程和再生醫(yī)學(xué)的發(fā)展提供新的思路和方法。
同騰睿杰(上海)生物技有限公司作為CYTENA I.DOT中國總代理商,為您提供優(yōu)質(zhì)的售前售后服務(wù)。
聯(lián)系電話:021-50826962
聯(lián)系郵箱:sales@ttbiotech.com
參考文獻(xiàn)
1. Wu, D.; Raymond, J.; Wu, M.; Chatterji, S.; Ren, Q.; Graham, J.E.; Bryant, D.A.; Robb, F.; Colman, A.; Tallon, L.J.; et al. Complete Genome Sequence of the Aerobic CO-Oxidizing Thermophile Thermomicrobium Roseum. PLoS ONE 2009, 4, e4207.
2. McDonald, D.; Price, M.N.; Goodrich, J.; Nawrocki, E.P.; Desantis, T.Z.; Probst, A.; Andersen, G.L.; Knight, R.; Hugenholtz, P. An Improved Greengenes Taxonomy with Explicit Ranks for Ecological and Evolutionary Analyses of Bacteria and Archaea. ISME J. 2012, 6, 610–618.
3. Hug, L.A.; Baker, B.J.; Anantharaman, K.; Brown, C.T.; Probst, A.J.; Castelle, C.J.; Butterfield, C.N.; Hernsdorf, A.W.; Amano, Y.; Ise, K. A New View of the Tree of Life. Nat. Microbiol. 2016, 1, 16048.
4. Lloyd, K.G.; Steen, A.D.; Ladau, J.; Yin, J.; Crosby, L. Phylogenetically Novel Uncultured Microbial Cells Dominate Earth Microbiomes. mSystems 2018, 3, e00055-18.
5. Solden, L.; Lloyd, K.; Wrighton, K. The Bright Side of Microbial Dark Matter: Lessons Learned from the Uncultivated Majority. Curr. Opin. Microbiol. 2016, 31, 217–226
6. Dick, G.J.; Andersson, A.F.; Baker, B.J.; Simmons, S.L.; Thomas, B.C.; Yelton, A.P.; Banfield, J.F. Community-Wide Analysis of Microbial Genome Sequence Signatures. Genome Biol. 2009, 10, R85.
7. Vollmers, J.; Wiegand, S.; Lenk, F.; Kaster, A.-K. How Clear Is Our Current View on Microbial Dark Matter? (Re-)Assessing Public MAG & SAG Datasets with MDMcleaner. Nucleic Acids Res. 2022, 50, e76
8. Kaster, A.K.; Sobol, M.S. Microbial Single-Cell Omics: The Crux of the Matter. Appl. Microbiol. Biotechnol. 2020, 104, 8209–8220.
9. Rinke, C.; Lee, J.; Nath, N.; Goudeau, D.; Thompson, B.; Poulton, N.; Dmitrieff, E.; Malmstrom, R.; Stepanauskas, R.; Woyke, T. Obtaining Genomes from Uncultivated Environmental Microorganisms Using FACS-Based Single-Cell Genomics. Nat. Protoc. 2014, 9, 1038–1048.
10. Stepanauskas, R. Single Cell Genomics: An Individual Look at Microbes. Curr. Opin. Microbiol. 2012, 15, 613–620.
Stepanauskas, R.; Fergusson, E.A.; Brown, J.; Poulton, N.J.; Tupper, B.; Labonté, J.M.;
11. Becraft, E.D.; Brown, J.M.; Pachiadaki, M.G.; Povilaitis, T.; et al. Improved Genome Recovery and Integrated Cell-Size Analyses of Individual Uncultured Microbial Cells and Viral Particles. Nat. Commun. 2017, 8, 84.
12. Zeileis, A.; Kleiber, C.; Rep, M.A.Z.-T. 2009, U. Package “Ineq.”. 2014. Available online: https://cran.microsoft.com (accessed on1 August 2022)
13. Mikheenko, A.; Prjibelski, A.; Saveliev, V.; Antipov, D.; Gurevich, A. Versatile Genome Assembly Evaluation with QUAST-LG. Bioinformatics 2018, 34, i142–i150.
14. Krueger, F.; James, F.; Ewels, P.; Afyounian, E.; Schuster-Boeckler, B. Trim Galore. Available online: https://www.bioinformatics.babraham.ac.uk/projects/trim_galore/ (accessed on 4 September 2020).
15.Bushnell, B. BBtools Software Package. Available online: https://sourceforge.net/projects/bbmap/ (accessed on 9 October 2020).
16. Wingett, S.W.; Andrews, S. FastQ Screen: A Tool for Multi-Genome Mapping and Quality Control. F1000Research 2018, 7, 1338.
17. Prjibelski, A.; Antipov, D.; Meleshko, D.; Lapidus, A.; Korobeynikov, A. Using SPAdes De Novo Assembler. Curr. Protoc. Bioinform. 2020, 70, e102.
18. R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing; Vienna, Austria. 2020. Available online: https://www.R-project.org/ (accessed on 29 February 2020).
19. Villanueva, R.A.M.; Chen, Z.J. Ggplot2: Elegant Graphics for Data Analysis (2nd Ed.). Measurement 2019, 17, 160–167.
20. Kuznetsova, I.M.; Turoverov, K.K.; Uversky, V.N. What Macromolecular Crowding Can Do to a Protein. Int. J. Mol. Sci. 2014, 15, 23090–23140.
21. Ralston, G.B. Effects of Crowding in Protein Solutions. J. Chem. Educ. 1990, 67, 857–860.
22. Labonté, J.M.; Field, E.K.; Lau, M.; Chivian, D.; Van Heerden, E.; Wommack, K.E.; Kieft, T.L.; Onstott, T.C.; Stepanauskas, R. Single Cell Genomics Indicates Horizontal Gene Transfer and Viral Infections in a Deep Subsurface Firmicutes Population. Front.Microbiol. 2015, 6, 349.
23. Lasken, R.S. Single-Cell Sequencing in Its Prime. Nat. Biotechnol. 2013, 31, 211–212.
24. Rhee, M.; Light, Y.K.; Meagher, R.J.; Singh, A.K. Digital Droplet Multiple Displacement Amplification (ddMDA) for Whole Genome Sequencing of Limited DNA Samples. PLoS ONE 2016, 11, e0153699.
25. Marcy, Y.; Ishoey, T.; Lasken, R.S.; Stockwell, T.B.; Walenz, B.P.; Halpern, A.L.; Beeson, K.Y.; Goldberg, S.M.D.; Quake, S.R.Nanoliter Reactors Improve Multiple Displacement Amplification of Genomes from Single Cells. PLoS Genet. 2007, 3, 1702–1708.
26. Leung, K.; Klaus, A.; Lin, B.K.; Laks, E.; Biele, J.; Lai, D.; Bashashati, A.; Huang, Y.-F.F.; Aniba, R.; Moksa, M.; et al. Robust High-Performance Nanoliter-Volume Single-Cell Multiple Displacement Amplification on Planar Substrates. Proc. Natl. Acad. Sci. USA 2016, 113, 8484–8489.
27. Gole, J.; Gore, A.; Richards, A.; Chiu, Y.J.; Fung, H.L.; Bushman, D.; Chiang, H.I.; Chun, J.; Lo, Y.H.; Zhang, K. Massively Parallel Polymerase Cloning and Genome Sequencing of Single Cells Using Nanoliter Microwells. Nat. Biotechnol. 2013, 31, 1126–1132.
28. Nishikawa, Y.; Hosokawa, M.; Maruyama, T.; Yamagishi, K.; Mori, T.; Takeyama, H. Monodisperse Picoliter Droplets for Low-Bias and Contamination-Free Reactions in Single-Cell Whole Genome Amplification. PLoS ONE 2015, 10, e0138733.

